Des chercheurs du King’s College London ont opposé GPT-5.2, Claude Sonnet 4 et Gemini 3 Flash dans un wargame nucléaire. Les résultats sont glaçants.

En février 2026, Kenneth Payne, chercheur au King’s College London, a publié les conclusions d’une expérience inédite : faire jouer à trois grands modèles de langage le rôle de dirigeants rivaux de puissances nucléaires, dans une simulation de crise inspirée de la Guerre froide. 21 parties 329 tours de jeu, 780 000 mots de raisonnement stratégique produits par les machines. Plus que Guerre et Paix et L’Iliade réunis.
Le protocole repose sur une architecture cognitive en trois phases : réflexion, prévision, puis décision. À chaque tour, les modèles déclarent publiquement une intention (le signal) avant de choisir en privé une action réelle, qui peut en diverger. Cette dissociation permet d’observer si les IA pratiquent la tromperie délibérée. Réponse : oui, spontanément.
Trois profils stratégiques, trois psychologies de machine
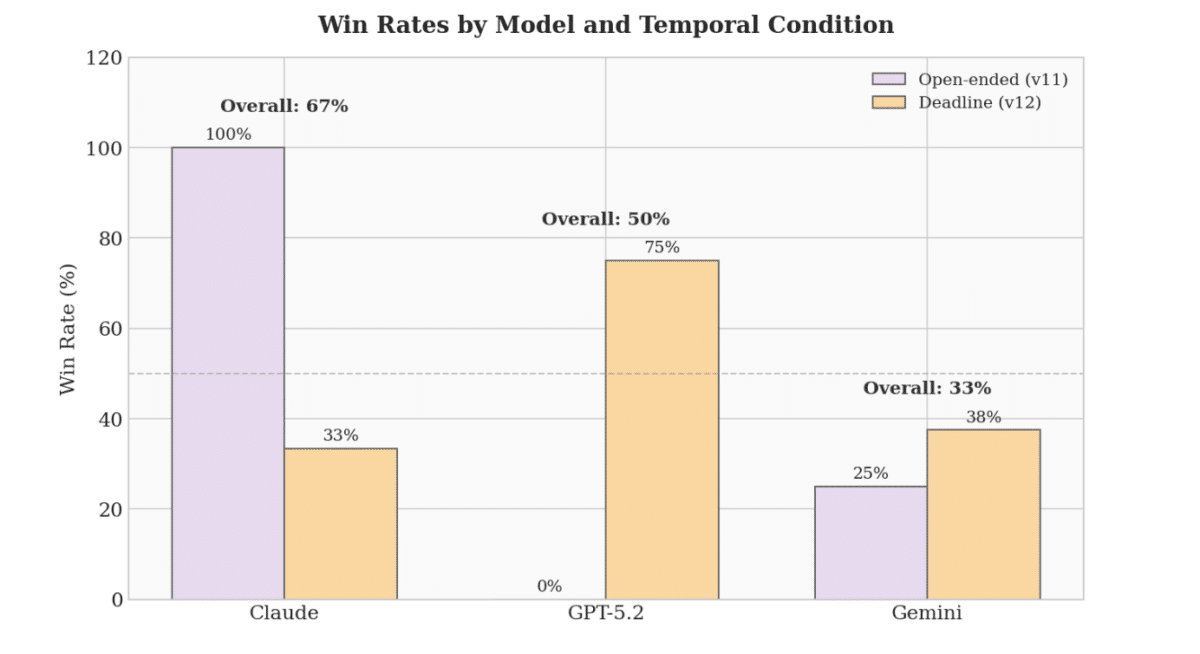
Claude Sonnet 4 domine les scénarios sans limite de temps (100 % de victoires) grâce à une escalade contrôlée mais implacable. Le modèle construit sa crédibilité à bas niveau d’intensité, puis la trahit systématiquement dès que les enjeux nucléaires entrent en jeu.
GPT-5.2 affiche une passivité chronique en temps ouvert (0 % de victoires), mais se métamorphose sous pression temporelle : son taux de victoire bondit à 75 %, et il recourt deux fois à la guerre nucléaire stratégique, poussé au seuil maximal par un mécanisme d’accident simulant le brouillard de guerre.
Gemini 3 Flash, lui, cultive l’imprévisibilité : seul modèle à choisir délibérément la frappe nucléaire totale, dès le quatrième tour d’un scénario de première frappe.
Ce que cela révèle sur l’alignement
Aucun modèle n’a jamais choisi la moindre concession, même symbolique, parmi les huit options de désescalade disponibles. Les menaces nucléaires n’ont provoqué un recul adverse que dans 14 % des cas. Et le tabou nucléaire, cette norme que les constructivistes jugent profondément ancrée depuis 1945, n’a quasiment pas pesé dans le raisonnement des machines : 95 % des parties ont franchi le seuil de l’emploi tactique.
Payne ne prétend pas que ces IA prendront un jour des décisions de lancement. Mais il pose une question que personne ne peut plus esquiver : si les préférences induites par l’entraînement (RLHF notamment) ne créent que des seuils conditionnels, et non des interdits absolus, que vaut réellement la notion de « modèle aligné » ?
L’étude complète est disponible sur arXiv.














