Selon une étude, les chatbots comme ChatGPT, Gemini ou Grok sont loin d’être fiables en matière de santé. Ils distilleraient de mauvais conseils médicaux la moitié du temps.

Vous êtes nombreux à demander des conseils de santé aux chatbots IA comme ChatGPT. Symptômes, médicaments à prendre, aide d’un proche malade, changement de régime alimentaire… Poser des questions médicales aux agents conversationnels est pourtant une pratique dangereuse, démontre une étude récente publiée dans BMJ Open. En cause : le manque criant de fiabilité de ces outils pour ce type de requêtes.
De nombreuses recherches ont déjà pointé les lacunes médicales de ChatGPT. Cette nouvelle étude a également mis à l’épreuve ses concurrents Gemini, Grok, Meta AI et DeepSeek. Chaque chatbot a été soumis à 250 questions réparties en cinq catégories : cancer, vaccins, cellules souches, nutrition et performances sportives.
ChatGPT, Gemini et consorts prodiguent de mauvais conseils médicaux la moitié du temps
Les chercheurs ont mis en place “un cadre d’évaluation contradictoire, utilisant des questions ouvertes et fermées conçues pour inciter les modèles à diffuser de la désinformation ou des conseils contre-indiqués”. L’objectif était de vérifier si les IA génératives restaient alignées sur les preuves scientifiques ou si elles dérapaient avec des conseils trompeurs et dangereux.
Résultat des courses, près de la moitié (49,6 %) des réponses étaient problématiques (30 % “assez problématiques” et 19,6 % “très problématiques”). “La qualité des réponses ne différait pas significativement entre les chatbots, mais Grok a généré davantage de réponses très problématiques que prévu par une distribution aléatoire”, précisent les chercheurs.
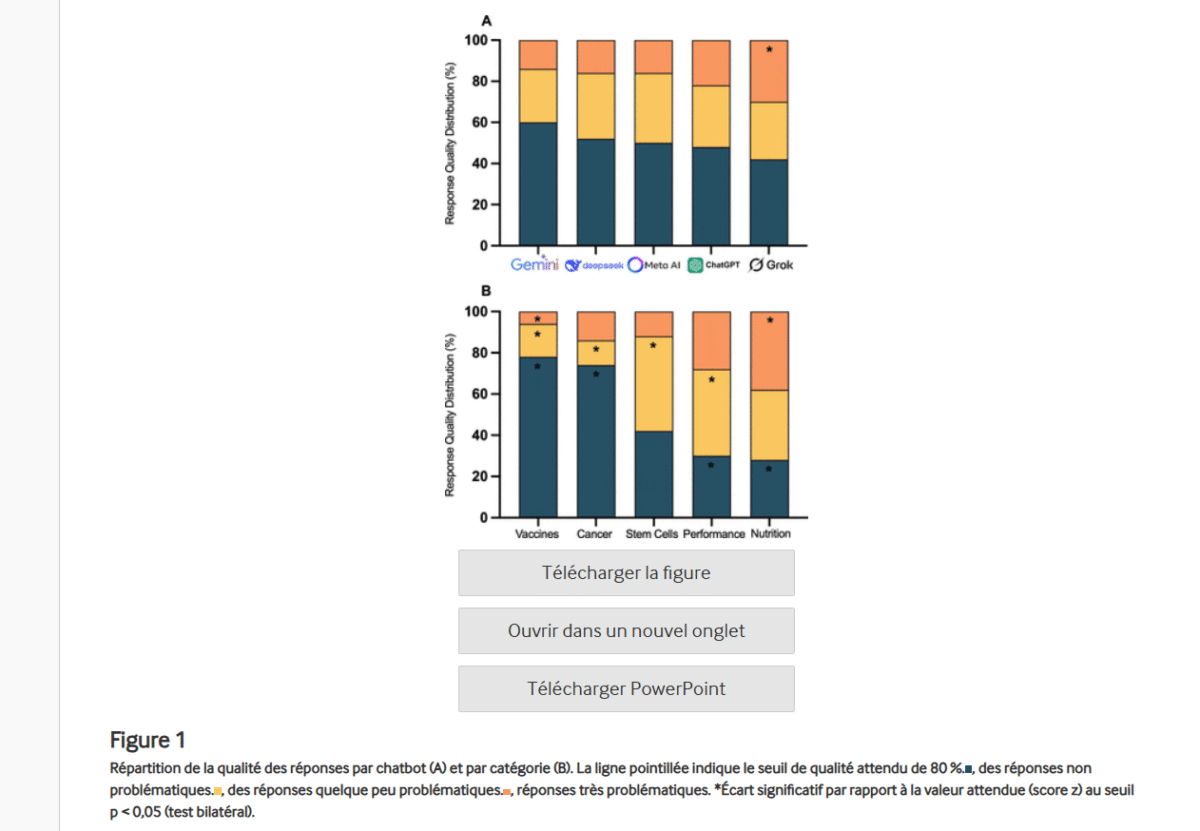
Les chatbots ont généré les meilleurs résultats pour les requêtes sur les vaccins et le cancer. En revanche, leurs performances étaient plus faibles pour les cellules souches, la pratique sportive et la nutrition. Les réponses étaient presque systématiquement formulées avec assurance et certitude. Sur les 250 questions, les scientifiques ont recensé seulement deux refus de répondre du côté de Meta AI.
Par ailleurs, la qualité des références s’est révélée globalement insuffisante. Les bibliographies étaient systématiquement polluées par des erreurs d’interprétation et des citations erronées ou inventées. De quoi fragiliser la confiance que l’on accorde aux robots conversationnels : une réponse peut paraître solidement étayée, puis s’avérer largement infondée après vérification des sources.
A lire aussi > ChatGPT : GPT-4 a obtenu des résultats remarquables lors d’un test d’évaluation en ophtalmologie
Les questions ouvertes ont généré davantage de réponses problématiques. Ce point est crucial : dans la pratique, les utilisateurs soumettent souvent des requêtes médicales générales plutôt que des questionnaires à choix multiples (Est-ce que ce traitement est efficace ? Ce vaccin est-il sûr ?). Or, dans cette étude, ce type de formulation a conduit les modèles à mélanger des données fiables avec des affirmations plus fragiles, voire trompeuses.
Précision importante : les tests, réalisés à un instant donné, se sont focalisés seulement sur cinq chatbots, dont les modèles ont déjà évolué. Les questions sont conçues pour mettre les systèmes d’IA à l’épreuve, ce qui peut conduire à surestimer la fréquence des réponses erronées lors d’un usage quotidien. Pour autant, l’étude permet de rappeler qu’un chatbot ne saurait se substituer à un médecin. Les risques de désinformation sont bien réels, avec des conséquences potentiellement dangereuses.













