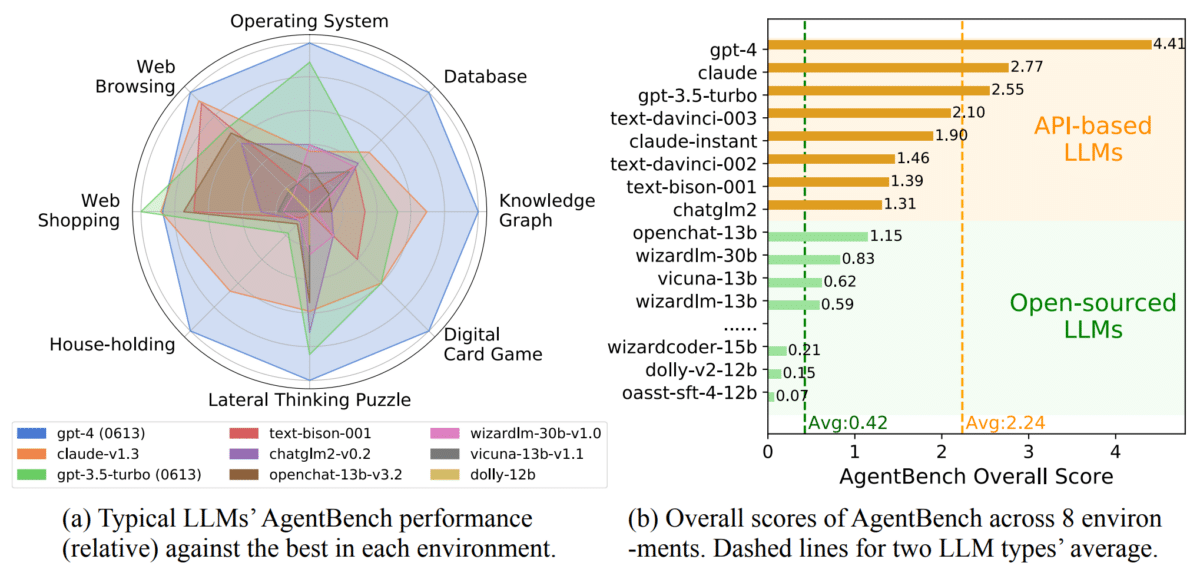
Le benchmark AgentBench révèle la grande supériorité de GPT-4 pour assurer des missions pratiques. Navigation Web, résolution de problème, traitement d’une base de données… le modèle de langage surclasse largement la concurrence.

GPT-4 est le modèle de langage phare d’OpenAI. Il est possible d’en profiter en payant pour ChatGPT Plus ou en passant tout simplement par Bing Chat. On le présente souvent comme le LLM le plus performant du marché. S’agit-il d’une idée reçue ou d’une vérité implacable ? Pour en savoir plus, nous vous proposons d’explorer les conclusions du benchmark AgentBench chapeauté par de chercheurs de l’Université Tsinghua, de l’Ohio State University et de l’UC Berkeley.
Celui-ci mesure les capacités d’assistance des grands modèles linguistiques dans “des missions pragmatiques de la vie réelle”. Le test se focalise sur les domaines suivants :
- Utiliser un système d’exploitation informatique
- Travailler avec des bases de données
- Travailler avec des graphes de connaissances
- Comprendre les jeux de cartes numériques et développer des stratégies
- Résoudre des problèmes en se montrant créatif
- Réaliser des tâches liées aux achats en ligne
- Naviguer sur Internet
GPT-4 sort largement vainqueur du benchmark
Alors que ChatGPT est accusé de faiblir ces derniers temps, le benchmark montre la grande supériorité de GPT-4 sur ses rivaux. Au total, les chercheurs ont testé 25 grands modèles de langage dont des modèles open source. Résultat des courses, GPT-4 a obtenu 4,41, soit le score global le plus élevé. Il était en tête dans quasiment toutes les disciplines hormis dans les achats en ligne dominés par son petit frère GPT-3,5.
Claude (Anthropic) se classe second au classement final avec un score global de 2,77. Il est suivi par le modèle gratuit GPT-3.5 Turbo d’OpenAI. Le score de performance moyen des modèles open source est seulement de 0,42 point. Selon les chercheurs, ils échouent généralement dans les tâches complexes et se font largement supplanter par GPT-3,5 qui propulse pour rappel la version gratuite de ChatGPT.
On regrette toutefois l’absence de certains LLM notables dans le benchmark comme PalM 2 et LaMDA, le modèle qui alimente Google Bard. L’équipe derrière AgentBench a publié les ensembles de données et l’environnement de référence sur Github pour permettre aux chercheurs de faire des comparaisons de performances plus approfondies.